Transformer
Transformer是一种采用注意力机制的深度学习架构,这一机制可以按输入数据各部分重要性的不同而分配不同的权重。于2017年由谷歌大脑的一个团队在论文《Attention Is All You Need》中提出,现已逐步取代长短期记忆(LSTM)等RNN模型成为了NLP问题的首选模型。并行化优势允许其在更大的数据集上进行训练。这也促成了BERT、GPT等预训练模型的发展。 ...
Transformer是一种采用注意力机制的深度学习架构,这一机制可以按输入数据各部分重要性的不同而分配不同的权重。于2017年由谷歌大脑的一个团队在论文《Attention Is All You Need》中提出,现已逐步取代长短期记忆(LSTM)等RNN模型成为了NLP问题的首选模型。并行化优势允许其在更大的数据集上进行训练。这也促成了BERT、GPT等预训练模型的发展。 ...
循环神经网络(Recurrent Neural Networks,RNNs)已经在众多自然语言处理(Natural Language Processing, NLP)中取得了巨大成功以及广泛应用。 ...

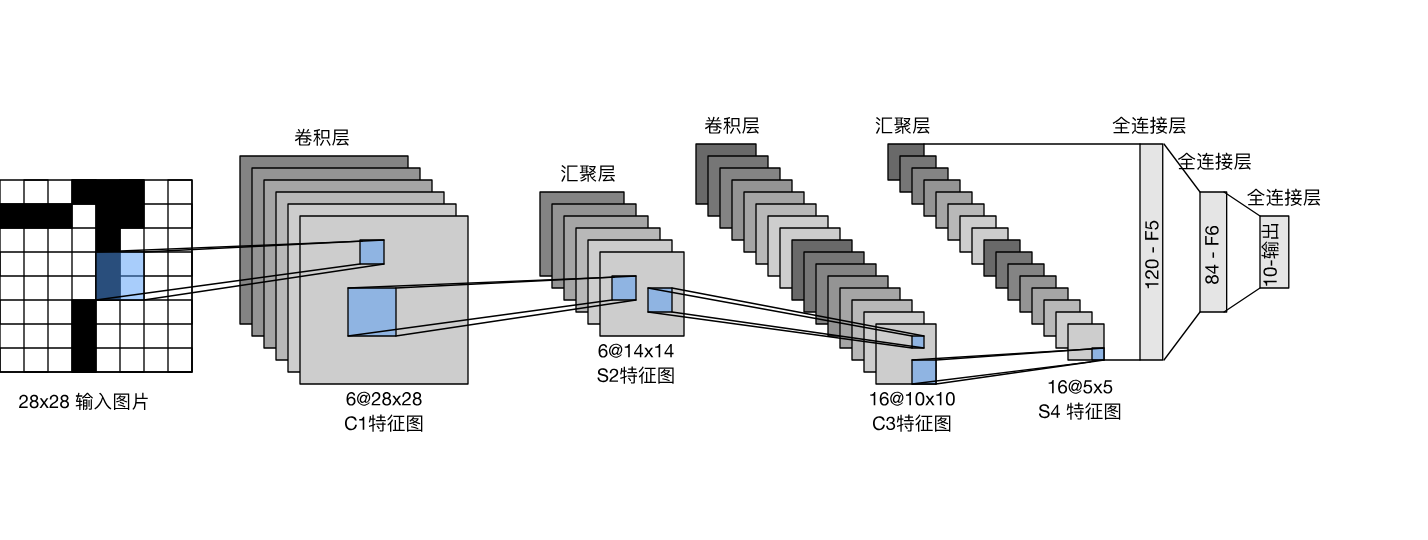
卷积神经网络(convolutional neural network,CNN)是一类强大的、为处理图像数据而设计的神经网络。 基于卷积神经网络架构的模型在计算机视觉领域中已经占主导地位,当今几乎所有的图像识别、目标检测或语义分割相关的学术竞赛和商业应用都以这种方法为基础。 ...
涉及深度学习计算的关键组件,即模型构建、参数访问与初始化、设计自定义层和块、将模型读写到磁盘,以及利用GPU实现显著的加速 ...
多层感知机在输出层和输入层之间增加一个或多个全连接隐藏层,并通过激活函数转换隐藏层的输出。 ...
softmax用来解决分类的问题 ...
线性回归是一种最基础的监督学习方法,用来研究输入特征和输出变量之间的线性关系。 ...
在深度学习中,通常通过梯度下降来优化代求的权重,就需要知道其梯度的方向,而一个模型往往有很多层,也可以看成由很多个函数的嵌套。我们常常需要求导数来进行权重的更新。 深度学习框架通过自动计算导数,即自动微分(automatic differentiation)来加快求导。 实际中,根据设计好的模型,系统会构建一个计算图(computational graph),来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。 这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。 ...
PyTorch中数据操作的一些简单笔记 ...
记录一些在Windows下安装PyTorch踩的坑。 ...